
The articles I found on Relational Database design are pretty dry and academic. The assumption is you are a seasoned Database Developer and you fully understand all of the terminology and why things like data types and columns are even needed.
They tell you to list all of your data points, what the primary key will be, who will access the data, how to handle indexing and start connecting them via foreign key assignments. DONE!?
Usually the individuals looking for examples and basics are not that familiar with DB structures yet. They will start creating a structure only to throw it all away later and start again with more knowledge. I thought I would try to create an example that follows a more logical approach for someone new to designing a new table for their relational database.
This is a very 101 and less-technical example. This is not really a tutorial so I’m gonna call this the “Stray Cat” method to database design 🙂
New Table Structure
In this example we are going to begin with the idea and start creating a table structure based on what we need to store as we go. When we need a new feature, key, relation or different structure we will backtrack and explain why.
Since this is a 101 example we are excluding things like “schema” and access control or stored procedures and data warehouse concerns. These are all very important but not so much for the newbie and understanding the concepts should come before the terminology in my opinion.
We will be using the “Table Designer” in ‘SQL Server management Studio” (SSMS) to create our table. You can just create a temporary database to follow through with this example.
Table Subject and Content
In our example we will not be creating a fully thought out block diagram with relations (as you should). Instead lets just assume we are going to have customers and go from there.
A customer could be a subscriber to your website or someone who walked in the door and purchased something. In either case we need to collect some info on our Customer and store it. Something like this would be the first table.
Table: Customers
| First_Name | VARCHAR(120) |
| Last_Name | VARCHAR(120) |
| VARCHAR(120) | |
| Phone | INT |
Datatype
In this table we only need to store text for the name and email so we are using a varchar datatype, with 120 characters max. We could also use a varchar for the phone number as it will store it the same way as it is typed.
What if the user types in parenthesis () or dashes for the phone number?
This will all be allowed using a varchar unless the front-end developer does some validation before storing it. For now we are assigning it as an Integer and will look at it again later.
Primary Key, Indexes and Duplicates
You could create the above table in SSMS and start inserting rows into it right now. The result would be basically a big spreadsheet stored as a database and defeat the whole point of relational DB’s. Let’s do better 🙂
We need to avoid putting in the same Customer more than once and keep the data orderly so the database engine can optimize things and the application can find records quickly. Our first design change is to add a primary key to the table.
The primary key is a field (not necessarily a number) that identifies every single record in the table uniquely with no duplicates. The application can quickly query records if it has the exact Primary Key to use. We are going to use an Integer here to accomplish this. Lets add an ID field to the table.
Table: Customers
| ID | INT |
| First_Name | VARCHAR(120) |
| Last_Name | VARCHAR(120) |
| VARCHAR(120) | |
| Phone | INT |
We now need to make this field unique by making it a Primary Key. The Primary Key will not allow NULL values and it provides a unique number that the application can use to find 1 record.
In SSMS you can just right click this field in the Table Designer and choose “Set Primary Key”. A little key icon will appear next to it and it will also no longer accept a NULL value so “Allow Nulls” will automatically be unchecked.
Note: When assigning the Primary Key there is also an index created by SSMS in the background called a “Clustered Index”. The Clustered index cannot contain duplicates so it’s what we need for this ID field, increase automatically and never repeat.
There’s no little yellow icon for this so you can see the Clustered Index by right clicking the ID field and choosing “Indexes/Keys”. It will be called something like “PK_Table_1” if you have not saved the table yet. There’s nothing to do here as the index is created when you save the table.
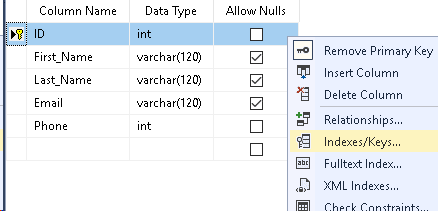
The NULL field is exactly as it sounds, it does or does not allow a NULL value when adding or updating a record. The Primary Key field cannot be a NULL because it is making each record unique using a number. We can never have 2 records with the same ID.
At this point we have a table that stores our customer data and requires only their First & Last Name and their email address, the phone is optional.
Insert Test Records
You can save the table, call it “Customers” and then you can try inserting records using SSMS. Use an INSERT statement or right click on the table and choose “Edit Top 200 Rows” to add records using the SSMS grid layout.
Note: If your using the grid to add records, they are not actually saved until you tab to the next record down or click away.
Lets add some customer records to the table using T-SQ, this code should work without issue.
INSERT INTO [Customers]
VALUES ( 3, 'Tanya', 'Blank', 'Blank134@email.com', '1231234567')
INSERT INTO [Customers]
VALUES ( 7, 'Sandra', 'Peris', 'periss@email.com', '1239876543')
INSERT INTO [Customers]
VALUES ( 9, 'Karl', 'Midfield', 'midfield@email.com', '1231231414')
SELECT * FROM CustomersNow lets try inserting a duplicate or a phone number that does not fit the datatype…
INSERT INTO [Customers]
VALUES ( 3, 'Christopher', 'Donnely', 'cdonnolly@email.com', '3334445555')
INSERT INTO [Customers]
VALUES ( 22, 'Christopher', 'Donnely', 'cdonnolly@email.com', '9999999999')These 2 statements should have resulted in 2 errors:
Violation of PRIMARY KEY constraint ‘PK_Customers’. Cannot insert duplicate key in object ‘dbo.Customers’
The conversion of the varchar value ‘9999999999’ overflowed an int column
What happened was we tried to insert and ID that already exists and then we tried to insert a phone number where the number or integer was too big to fit. We can first fix the ID field so its handled by SQL Server instead of the application.
Identity ID Column
The first issue is the ID field which cannot be duplicated since its a Primary Key. Fortunately SQL server has the ability to assign this number automatically and keep the field unique. We need to make the ID field an IDENTITY column and assign it a start and increment.
To do this open the Table in Designer again and highlight the ID field. In the Column Properties pane scroll to the “Identity Specification” section and change the “Is Identity” option to YES and save the table.
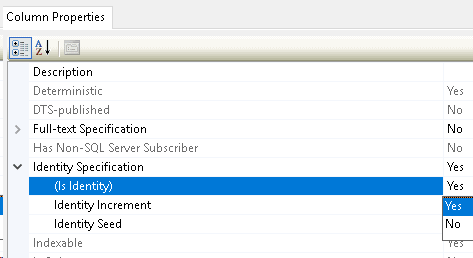
The “Increment” and “Seed” options allow us to assign a starting number and how much the field will increment for each record. We could, for example, start with 10 and increment by 20. The records ID would look like this starting at 10 and incrementing by 20:
- 10
- 30
- 50
- 70
We are going to use the default here which increments by 1 for each record we insert into the table. Now we do not need to include the ID field when inserting records as the service handles that for us. We remove the ID field as part of the statement and insert again. Try this..
INSERT INTO [Customers]
VALUES ( 'Christopher', 'Donnely', 'cdonnolly@email.com', '1231231234')
INSERT INTO [Customers]
VALUES ( 'Tracy', 'China', 'tchina@email.com', '1231231234')
SELECT * FROM CustomersYou will see that the ID field is populated and incrementing by 1 for each record. We can now insert records where each one is unique and return them using the ID field and our Primary Key Clustered Index.
Try running the above INSERT more than once, maybe 4 or 5 times?
You will see that the records are inserted each time and the ID increments but the problem is we now have duplicate customers. The application would need to check and see if the customer exists using some field or combination of fields that would be unique to each customer.
Primary Keys and Indexes
You might have guessed that the email and phone fields could be used as they are more unique for each customer. From a design perspective it would not be a horrible idea to change our Primary Key ID field to the email field instead, but there are costs to this.
The reason we use an integer is that the number of records possible, using a positive integer, is 2,147,483,647 or over 2 Billion records. The Datatype range is actually -2,147,483,647 to 2,147,483,647 or over 4 Billion records. The SQL engine can quickly parse and locate an integer must faster than a character field where it needs to match each character in the email before finding the one it needs.
Unique Indexes
In this example we only need to keep our application from creating the same customer more than once. We will choose the email field to let us know if the customer is new or unique and can be added to the table or rejected since they already exist.
To restrict this field from creating duplicates we can create a unique index and we do this buy going back to the Table Designer. Right click on the “Email” field and choose “Indexes and Keys” as we did before.
You will see the Primary Key that was created previously and an Add button at the bottom.
Click “Add” to add our new index to the table and change the (Name) to “IX_Customers_Email”.
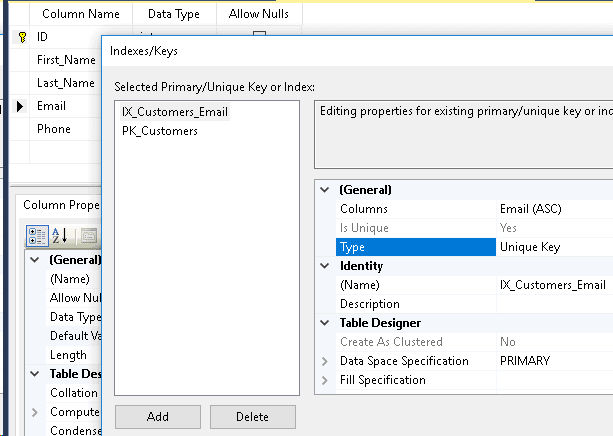
Change the “Column” to the “Email” column name and then click the “Type” and select “Unique Key” from the drop down. You may notice that the “Is Unique” option is grey’d out and says Yes. Now update the name calling it “IX_Customer_Email” .
In this case we only need to force the email field to be unique so “Unique Key” is the only option necessary. You can now close and save the table. Clear the table by truncating it…
Truncate Table Customer;Try running the INSERT a few times, you should get errors for the duplicate email addresses. Also, if you change the email address to something that does NOT exist it should work fine.
INSERT INTO [Customers]
VALUES ( 'Christopher', 'Donnely', 'cdonnolly@email.com', '1231231234')
INSERT INTO [Customers]
VALUES ( 'Tracy', 'China', 'tchina@email.com', '1231231234')
SELECT * FROM CustomersViolation of UNIQUE KEY constraint ‘IX_Customers_Email’. Cannot insert duplicate key in object ‘dbo.Customers’.
Phone Numbers & Design
The last subject we will look at is the phone number field. The phone has multiple components and can be designed differently depending on your database needs. There is a country code as well as an area code that both could be separated for application GUI reasons.
We could just shove everything into a string and save it as a varchar but this would make it tough to split the area code or country code. Not to mention they could add dashes and parenthesis to the number. In our example we are only dealing with the US so we have an area code and number to deal with.
| ID | INT IDENTITY (1,1) |
| First_Name | VARCHAR(120) |
| Last_Name | VARCHAR(120) |
| Email (Unique) | VARCHAR(120) |
| Phone_Area | TINYINT |
| Phone | INT |
The Area code is only 3 digits so I was able to use the TINYINT and save some data space. The Phone field will only have the 7 digits so the application will need to put these 2 fields together to display a valid phone number or make it clickable to the user.
Normalize
An application may need to store multiple phone numbers for a single Company because they have more than 1 location and many contacts. They could also be in other countries and this might be important for the application function or to decide what to or NOT to display.
For a real application these data points would probably be separated into their own tables. The Customer name and email might be together with any account info or even a password hash but the phone and any address info could reside in a contact table or address table.
A contact table could be One-to-Many where the 1 Customer has Many methods of contact. This could be Phone, Address, Email, Social Media, Websites or more.